
Global Spare Parts Search
Stop searching, start finding

-min.jpg?width=300&name=Resources_Menu%20(3)-min.jpg)

.png?width=300&name=BOM_Self_Service_Header%20(1).png)
Key takeaways
Duplicate material masters drive significant cost and complexity: Poor master data quality, often caused by mergers, weak search processes, and human error, leads to excess inventory, inaccurate reporting, data migration delays, and unnecessary costs. On average, duplicates can represent substantial tied-up stock value.
Clean data is foundational for efficiency and system migrations: Accurate and duplicate-free material data improves transparency, reduces manual effort, and simplifies projects such as SAP ECC to S/4HANA migrations. The cost of correcting errors increases dramatically the longer they remain unresolved.
Structured deduplication requires governance and clear rules: Sustainable duplicate removal depends on defined policies, guiding principles, stakeholder alignment, and a clear decision framework, especially for selecting the leading (“Parent”) material and handling dependent (“Child”) materials.
A phased process ensures controlled cleanup: Effective deduplication follows a structured approach: audit the data to surface and validate duplicates, analyzing dependencies and effort, defining leading materials, preparing an implementation plan, and executing the cleanup in a controlled manner
Automation Accelerates and Sustains Data Quality: Manual identification of duplicates is resource-intensive. Software solutions like SPARETECH use matching algorithms and manufacturer data comparisons to detect duplicates and obsolete parts, reducing manual workload and embedding data quality into ongoing operations.
Background: Poor Master Data Quality
Many companies struggle with the quality of their master data. Poor data quality can be associated with data redundancies, data inaccuracies, or outdated information. These lead to inaccurate reporting, increased time spent migrating to a new system, excess inventory, and employee dissatisfaction.
Data redundancy can usually occur during companies’ mergers and acquisitions. Master data duplicates are also possible due to the difficult and inaccurate search process step and human error when users create duplicate items without a proper duplicate check performed upfront.
During these turbulent times, organizations focus on process improvements and cost-reduction initiatives. Clean, duplicate-free master data is the foundation for efficient day-to-day activities. Moreover many companies these days are planning a migration to new software (for example from ECC to S/4HANA) and the need to have clean master data is becoming a priority.
This blog will cover the Material Master data deduplication process.
Why is it important to keep your material master data clean and free of duplicates?
No one likes to work with poor-quality data. Poor data leads to wrong decisions, frustrations, and trust issues and it costs a lot of money to organizations as well. For example, our clients have 9% duplicates on average and that is about 1 Mio € of stock. The price of doing nothing is high. The longer it takes to identify and correct data entry errors the higher price. Rule 1-10-100 states that it costs 1€ to verify the data being entered, 10€ to clean the data after the fact, and 100€ if you do nothing.
Accurate, consistent, and duplicate-free data, on the other hand, contributes to process improvements and saves time and money by reducing complexity and manual activities (for example: during migration/implementation projects). The following figure depicts the benefits of clean master data free of duplicates.
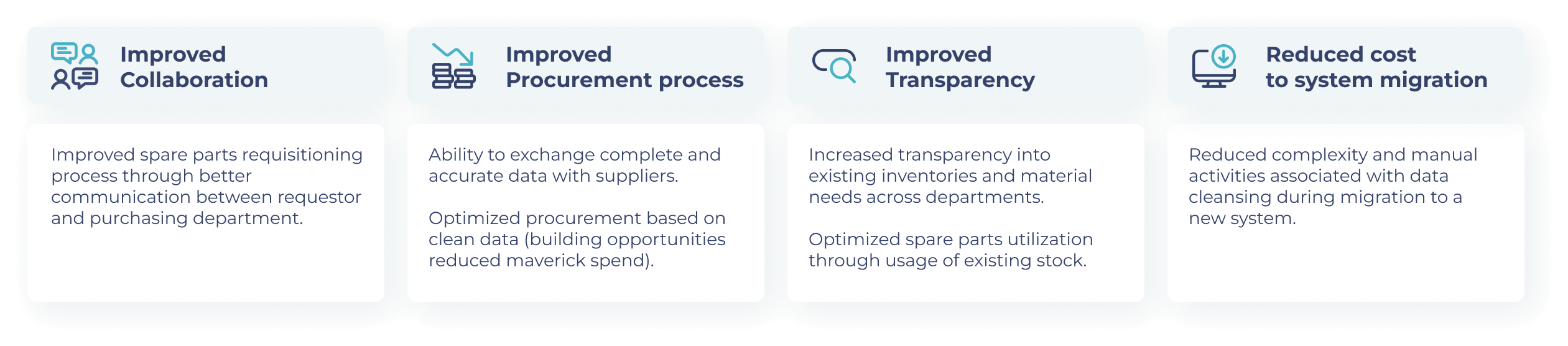
Figure 1. Benefits of clean master data without duplicates
Remove duplicates from the material master - where to start?
The process for removing duplicates varies from company to company and depends on company size, established processes, available resources, and tools. However, the structure below can be seen as a rough framework applicable to any company.
To gain benefits and ensure your data is ready for migration to a new environment or to proactively prevent duplicate items from entering your systems, you need to think within the following four categories: Policy and Guidelines, Delivery model and People, Processes, and Technology and Tools.
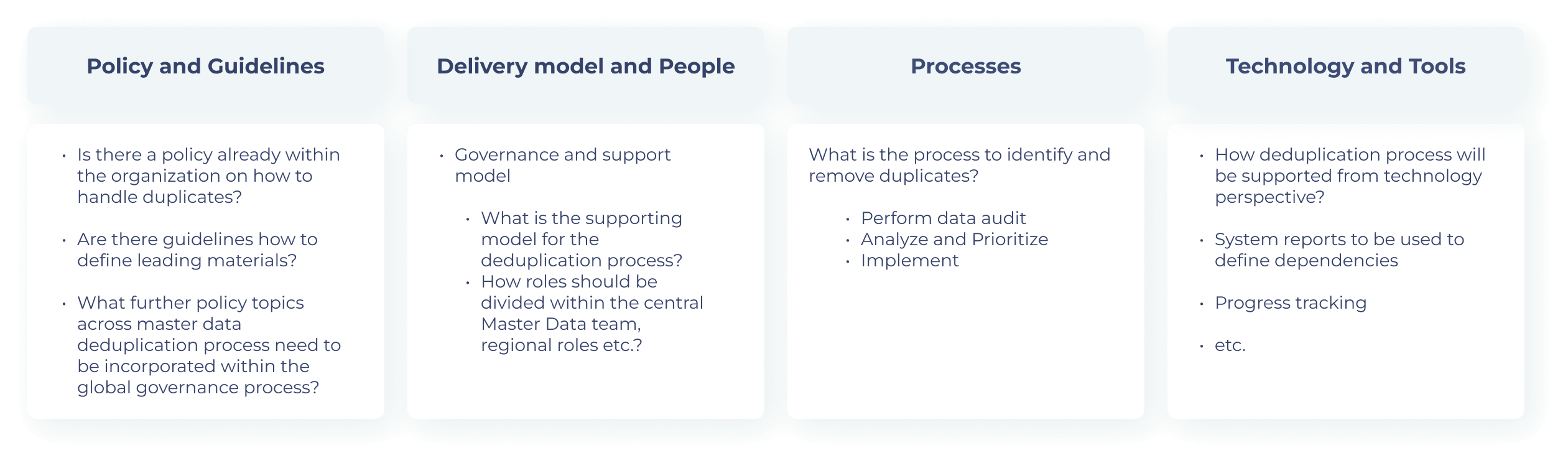
Figure 2. key decisions for sustainable duplicate removal.
Policy and guidelines
Before you start removing duplicates, it is best to understand whether there is already a policy within your organization on how to handle duplicates and whether there are guidelines for defining a leading material. This could be already available on a global level for different types of materials for some organizations, however, for many of our customers, this topic is new for spare parts. This is a great opportunity to start and prepare internal guidelines on duplicate removal and how to prevent this from happening.
Establishing guiding principles for the process can be a good starting point.
Customer examples of guiding principles:
- Ensure business continuity at any time
- Ensure transparency
- Avoid double effort
Delivery model and people
Cleaning up your data, especially removing duplicates from the system can be a lengthy process, hence it is important to have a governance and support model in place. Removing duplicates is a collaborative effort and involves various stakeholders, from regional teams to the central master data team. Make sure everyone is on-board and understands the project structure, decision-making process, and communication procedures.
Processes
As Figure 3 indicates, the deduplication process commences with a solid plan that starts with auditing, analyzing, and prioritizing your data before applying the insights in your ERP system.

Figure 3. Three-step process for removing duplicates.
1. Perform data audit
Whether you are performing a mass data cleansing of duplicates or creating a new material as a part of day-to-day business, the process starts with evaluating the data and identifying potential duplicate records in the system.
When assessing the data, you should validate the correctness of suggested duplicates and whether additional steps are needed - for example, get an expert opinion or request further information.
2. Analyze and prioritize
2.1 Define dependencies
Once the input data is validated, the next step is to identify the material dependencies. Identified duplicates could already be in use in your ERP - for example, there could be an open purchase order or available stock. These follow-up documents and inventories have to be identified and mapped in the system to ensure the complete picture is taken into account prior to taking the next steps.
When identifying dependencies think within the system perspective as well as any other dependencies, such as stakeholders, documentation, and stock labels.
The dependencies will be unique for every organization based on the configuration, however, you can think of the following:
ERP system dependencies:
- Available stock per material and location
- Open order
- Maintenance plans
- Parts lists
- Contracts
- Reservations
Other dependencies:
- Other system dependencies (Are there other systems that are affected?).
- Limiting conditions (Are there any limiting conditions that may affect the process of defining the leading material?)
- Stakeholders (Which stakeholders need to be involved in the process?)
- Internal documentation
- Labels (Is a relabeling process required?).
Tip for SAP users: how to find dependent objects for the material master: SARA transaction→ select object "MM_MATNR" → click on the icon of the network graphic. Here you can see an overview of the dependent objects in the material master. More info.
2.2 Assess efforts
Once all dependencies have been identified, you should estimate the effort needed to make those adjustments in the system to master data and transactional data, as well as non-system-related efforts.
2.3 Define leading materials
How to define leading materials is probably the crux of the deduplication process. Many of our customers struggle to design the decision tree, however a clear picture of all dependencies and an effort estimation ensure that the process is supported by the necessary input.
We recommend focusing on criteria and rules for your organization that help to streamline the process.
Customer examples:
- “Our goal is to minimize the overall effort; the material with the highest effort to change will become the leading material”
- “In the case that all materials of the duplicate group are used across the same plants and there are no other restrictive conditions, then the older material number will be defined as the leading material number”
- “If one of the duplicate materials is used across various plants and others are only used for one, then the first one will be the leading material, regardless of the date of creation. This prevents the complicated and time-consuming communication between several plants/storage locations and the time-consuming re-labeling at various locations”
2.4 Prepare implementation plan
When “Parent” and “Child” materials are identified, the responsibility of the core team is to set up an implementation plan to ensure the project runs smoothly and the scope is clear.
A solid foundation for such an implementation plan will consist of: a defined scope of actions per “Parent” and “Child” materials, a core team structure to perform actions, a meeting cadence and communication approach, and an estimated timeline.
While working on the implementation plan, individual decisions must be made for each material.
For "Parent" materials:
- Some of the characteristics need to be updated based on the information from the "Child" materials.
For "Child" materials:
- The status of the material must be updated:
- Will “Child” materials be blocked for procurement? If the deactivation process is lengthy then a material might need to be available for re-ordering.
- When should “Child” materials be marked for deletion? Usually, when stock is removed and no one needs to use this material anymore, this could be marked for deletion.
3. Implement
The process of removing duplicates can take up to a year. The defined implementation plan will help your team to remove duplicates and apply changes in your ERP system, update documentation and re-label stock if needed.
Key activities:
- Eliminate dependencies (Close open POs, remove stock, update dependent objects, etc)
- Extend leading materials with missing characteristics
- Inform all relevant stakeholders
- Deactivate material: Block for usage / Mark for deletion of non-leading materials
- Update documentation
- Re-label stock
Technology and Tools
Manually searching through thousands of spare parts master data and identifying duplicates is a mammoth task and can seem nearly impossible depending on the size of your material master. Data cleansing is often neglected for years or difficult to implement due to a lack of tools and processes.
Software tools such as SPARETECH can greatly facilitate the process of identifying and removing duplicates. By using matching algorithms and comparing the material information to original manufacturer data, material masters can be automatically scanned for duplicates and obsolete spare parts. This way, the manual effort for maintenance staff can be significantly reduced.
Learn more about how automation software like SPARETECH can help you clean your master data in this explainer video.
Conclusion
Accurate and consistent master data is the key to process improvements and transparency in industrial spare parts. Needless to say, good data will bring more trust into the data. Using software tools like SPARETECH early in the spare part requisition process, as well as part of master data cleansing activities, unlocks insights for the maintenance and master data teams and drives data-informed decisions within the organization.
An effective approach to the process of removing duplicates can help to boost your data quality and reduce manual work during migration to a new system. It probably goes without saying that this is not only a one-time mass cleansing activity but an ongoing process as well. It is critical to create a culture of keeping your data clean and keeping your system free of duplicates. This can include things like training employees on how to properly enter materials into the material master, implementing quality control measures and specialized software, as well as restricting the number of users who can create a material master in the system.
- Analyze your master data closely and identify duplicates as early as possible.
Catch data problems at the beginning of the master data creation process and prevent duplicates from entering the ERP system.
- Establish a process and project team to coordinate the deduplication process.
The process of removing duplicates can be lengthy and requires input from various stakeholders - it is best to set up a core project team and ensure everyone is on-board.
- Use tools to help you identify duplicates and improve the quality of your spare parts data.
Use software tools to make day-to-day activities more efficient and make it easier to identify duplicates. Using the right automation tool in combination with the duplicate elimination process will add real value.
Reach out to the SPARETECH team to learn more about how we can support you on your journey to improve data quality.


Lena Luckert, Lead Product Manager at SPARETECH, builds digital solutions that help manufacturers optimize spare parts management and maintenance operations. Her background in industrial engineering and product management supports the development of efficient, data-driven MRO workflows.
Expert tip: Treat duplicate removal as a controlled “material master consolidation” program, not a one-time data-cleanup task
One clean-up wave without master data governance just recreates duplicates later.
- Define what “duplicate” means for your material master: for example based on identical original equipment manufacturer (OEM) part number, form-fit-function equivalence, or “same description”.
- Run dependency mapping before any blocking/deletion (BOMs, task lists, maintenance plans, reservations, open purchase orders, stock by storage location, batch, or serial number).
- Build a leading-material decision tree that optimizes for the lowest change effort + the lowest downtime risk (BOMs, preventive maintenance plan, stock, purchase order history are typically decisive).
- Implement post-merge controls: block non-leading materials, redirect procurement, and relabel rules.
- Enforce one front door for creation (central team or master data governance workflow) with mandatory duplicate checks + manufacturer reference enrichment.
Done right, you reduce working capital tied to redundant stock and remove hidden failure modes in maintenance execution.